Jun 15, 2026
Last Friday an AI Model Just Vanished
Everyone's asking how to squeeze more intelligence out of their AI budget.

Last Friday night, Anthropic took its two most powerful models, Mythos and Fable, offline, after the White House hit the company with export controls.
Not because the models broke. Not because they produced bad outputs. A standoff between a frontier lab and the administration, over a cyber order and fears the models could be jailbroken, meant that if Fable was the AI your team ran on, it went dark overnight. No warning, no migration window, and no explanation.
The politics matter less than what it means: single-model dependence is a liability, and it just became starkly visible.
And yet, the question I keep getting from leaders, especially those actively evaluating AI tools for their teams, is:
“How much intelligence/AI can I squeeze out of my budget?”
The Recurring Mistake: Technology First, People Second

The intelligence-per-token question is a technology-first question. And technology-first is how organizations end up with AI tools nobody uses, rollouts that stall as pilots, and frustrated operators who’ve been handed a hammer and told to go find nails.
The pattern is painfully predictable. Leadership picks a model based on benchmark scores or slick sales demo. The IT team builds workflows around that model. Your co-workers who need it daily encounter the tool, decide it doesn’t fit how they work, and go back to their personal ChatGPT. Six months later, you’ve got expensive infrastructure and everyone is frustrated with the lack of value.
We can do better. Let’s start with the people…
Every Frontier Model Is Already Smart Enough
Every major frontier model is good enough for 80% of the work that your organization is going to do.
GPT-5.5, Claude, and Gemini. They can all read a complex brief, reason through ambiguity, draft structured content, and surface insights from a document dump. The differences at the margin matter for specific jobs, but the baseline intelligence gap between the top models is smaller than it’s ever been. We crossed a threshold somewhere in the last 6 months where the question shifted from “is this model smart enough?” to “does this model fit how our organization wants to work?”
For Your Organization?

Consider four organizations, all roughly equivalent in “needing an AI”:
The 12-person nonprofit with zero budget and a team that will never have a developer supporting them. Their data is sensitive: donor information, beneficiary records. They need something their program coordinator can use without a training week. Ease of onboarding and data privacy terms matter more than benchmark scores. They need a clean, accessible interface and an AI whose data-handling terms they can actually read and explain to their board.
The company supporting 100 developers who already live in the terminal and want AI embedded in their code editors. Speed, API access, token cost, and code-specific performance dominate the decision. The model that’s “smartest” in a general sense might not be the one with the best code completion at the file context length they need.
The regulated enterprise in financial services, healthcare, or legal, where every output is a potential audit artifact. They need on-premise enterprise options, SOC 2 compliance, data residency guarantees, and a vendor relationship that can survive a procurement process. The newest cutting-edge model from a two-year-old startup probably isn’t the answer, no matter what the benchmarks say.
The scrappy 35-person agency running client deliverables at volume. They need fast iteration, broad capability across content types, and pricing that scales with output rather than seats. They probably can’t afford to have their entire workflow depend on a single provider’s pricing decision.
Same “intelligence.” Four completely different right answers.
Before You Pick a Model, Answer These Five Questions
Before you open a pricing page, spend some time wrestling with these:
-
Who actually uses this daily? Not the enthusiastic early adopter who submitted the budget request. The person who’ll open this tool on a Tuesday afternoon when they’re behind on three other things. What’s their technical comfort level? What does their existing workflow look like? Who is going to support them in the hill climb to success?
-
What’s your risk tolerance and data sensitivity? Are you putting proprietary client data, employee records, or regulated information into prompts? Your answer here isn’t just a preference; it constrains which vendors can legally be on your shortlist.
-
What does a failure cost? If the model produces a bad output, who catches it before it reaches a client or a customer? If the answer is “nobody” or “the model itself,” your failure cost is high and you may need a more conservative pick.
-
What’s the real budget? Not the sticker price on the API. The total cost of ownership, including the human time to evaluate, implement, train people on, and maintain whatever you choose. A “cheaper” model that needs three months of integration work isn’t cheaper.
-
What can your organization actually adopt and sustain? A model that requires custom API integration is a different commitment than a chat interface. Be honest about your team’s capacity to build and maintain infrastructure. The best AI for your organization may be the one not killing you in technical debt six months from now.
Answer those five, and the budget question gets much easier. You’ve already eliminated most of the options.
Don’t Marry One Model
A few weeks ago, I wrote about why I run two AI tools side by side. The argument was that specialization beats picking a single winner. The Fable shutoff added something I didn’t fully weigh at the time: redundancy isn’t just about performance. It’s about continuity of operations.
I run three stacks daily: Claude, OpenAI, and OpenRouter. If something happened to one of them tomorrow (a shutdown, a pricing spike, an acquisition that changed the terms of use), I don’t lose my entire workflow. I lose a third of it. That’s recoverable.
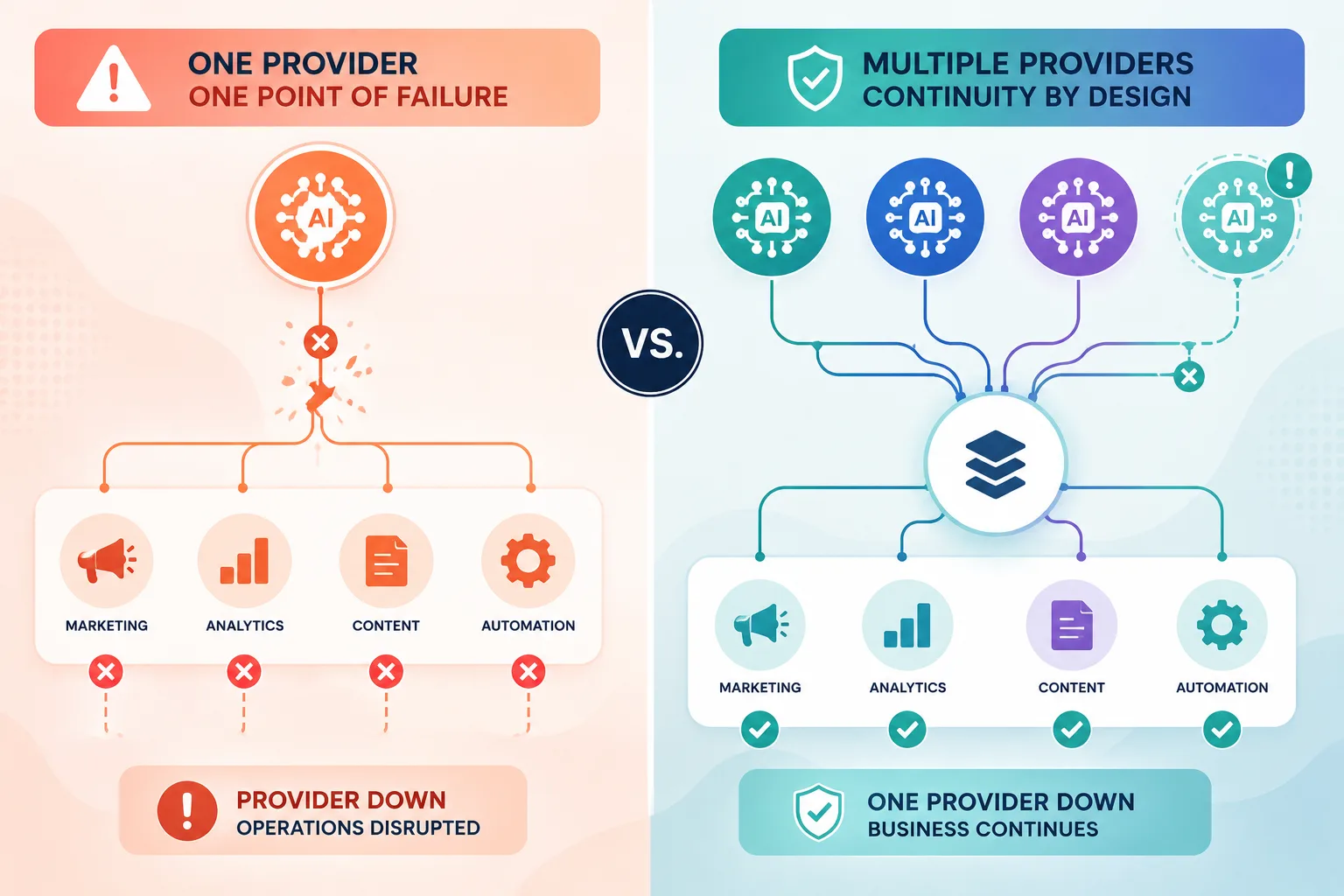
The Fable situation is exactly why. The model didn’t fail. The model didn’t even get worse. A decision was made above the organizations that depended on it, and we had no recourse. That’s a different kind of risk than a bad benchmark score, and it doesn’t show up on any vendor comparison chart.
Running three models isn’t paranoia. It’s how you build continuity into a workflow that increasingly depends on AI to function.
Start with the People
It’s easy to start with a tech, but our obligation as leaders is to make our teams successful.
Have you done your part to support your team in a sea change that will arguably be larger than the rollout of the Internet?
Start with supporting the people. The tech should follow.